How To Backup ZFS Datasets with zrep
October 23, 2018. 1340 words.
The most frequent reasons for data loss are (in roughly that order) user stupidity, malicious software, physical theft, coffee poured over disks (a subset of user stupidity worh mentioning) and actual hardware failure.
When ensuring against the first two with ZFS snapshots, replicating actual snapshots to backup machines may be preferable to rsync-walking large filesystems on slow storage.
zrep is a program which may facilitate that process considerably.
Principle
SnapshotsSnapshot (computer storage). Wikipedia, How Are Filesystem Snapshots Different from Simply Making a Copy of the Files. StackExchange. are a filesystem technique where past filesystem state may be held read-only in parallel to current state. Then, read-only, past state may ensure against data loss due to deletion, tampering or even malicious encryption. Even when the actual state is lost, a file’s content may be still recovered from the snapshot.
When sets of snapshots are constructed so that disk space is freed only then, when no snapshot references are left pointing at a set of disk blocks, then the filesystem state difference-sets may be passed between machines in an incremental fashion.
Consider a data set on machine M with states D0, D1, D2, …, DT.
Consider, also, a machine K holding the the same data set, but only with states D0, D1.
Then, to transfer the state of machine M to K, is is sufficient to transfer the states D2, … DT.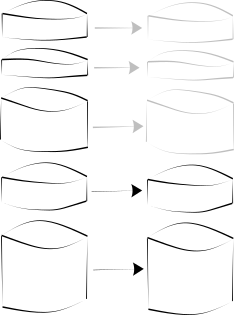
Transferring ZFS Snapshots.
Novelty
This is, by no means, a new approach.
tar offers incremental archive sets for ages and rsync, the de-facto standard for incremental file transfer, transfers not only files, but file parts for ages as well.
So, what makes sending incremental datasets superior?
Comparing case-wise:
Incremental tar-files are not cheap storage-wise.
When any data set is archived (and compressed?) using tar, an additional copy is stored per file set, so the data is at least duplicated.
In addition, tar-files are not particularly resilient to errors or corruption.
When files become corrupted even if only in parts, the files following cannot be placed on top.
rsyncing files across machine boundaries is cheap storage-wise, because no additional copies are needed.
rsync compares local and remote file’s contents using a sliding window algorithm with checksums and transfers the sliding window part only if the checksums do not match, so it is manageable compute-wise.Tridgell & Mackerras. The rsync algorithm. 1996.
Because each and every file must be read in to be compared, it is by no means cheap I/O-wise.
Replicating data sets based on filesystem snapshots is cheap in all three cases: It is storage-efficient, because data is stored only once. It is compute efficient, because no data set differences need to be calculated, as the separation points between diffs are already known - these are the snapshot points. For the same reason, it is I/O efficient: It is already known which data needs to be transferred and only file system meta-data (few kB) needs to be read in.
Algorithm
On snapshottable filesystems, the algorithm thus is roughly as follows:
First, determine the latest common snapshot on both local and remote filesystem. Then, secondly, snapshot the local filesystem and then thirdly, transfer the increment ranging from the (already determined) latest common snapshot to the current snapshot to synchronize.
Tooling
While the algorithm seems simple, with a large number of filesystems or a high frequency of snapshot transfers, the approach soon will become unwieldy.
Phillip Brown’s zrepzrep Documentation, zrep Code. , originally intended for failover replication, neatly reduces the multiple snapshotting and sending invocations in a one-liner by means of roughly a thousand lines of ksh.
Requirements
zrep must be installed on both systems, the backup server and the client, called the backupee here.
The server and client systems must be configured so that from the backup server, access to the client dataset is possible over ssh.
Even when dealing with datasets, this is not necessarily the root user. On Solaris, permissions on ZFS datasets may be delegated to non-root users unconditionally using zfs allowOracle Solaris 11.3 Information Library, Managing ZFS File Systems in Oracle® Solaris 11.3, valid for lesser versions. .
Because mount-operations are restricted on other systems, this additionally requires to set the sysctl-tunable vfs.usermount on FreeBSDFreeBSD Handbook. Chapter 19. The Z File System (ZFS), §19.5. .
On Linux, there is currently no possibility to delegate mounting to users apart from using zfs legacy mount properties, which is a very unwieldy solution.
Create datasets for zrep
Note that the term dataset on ZFS-systems in analogous to filesystems. I denominate a set of data as a file set instead. First, create a dataset on the backup server
<backupsrv> $ zfs create zpool/backup/mccarthy-cjr
We assume, that a dataset is already present on the backupee. Because ideally, the data transfer itself should not require root privileges, delegate ZFS permissions to the user on the client
<backupee> $ zfs allow \
-dl \
<user> \
create,destroy,hold,mount,receive,rename,rollback,send,snapshot,userprop
<dataset>
Note that the mount permission is necessary to delete ZFS datasets, even when it is impossible to delegate the mount capability on the specific operating system.
Also note that it is necessary to delegate permissions on the local dataset as on descendant datasets (-dl). No root privileges are required beyond this step.
Seed
zrep uses ZFs dataset properties, so set
<backupee> $ zrep changeconfig -f \
data/to/be/back/upped \
backupsrv \
backup/target/fs
which will result in
$ zfs get all data/to/be/back/upped | grep zrep
data/to/be/back/upped zrep:dest-host backupsrv local
data/to/be/back/upped zrep:savecount 5 local
data/to/be/back/upped zrep:src-host mccarthy local
data/to/be/back/upped zrep:dest-fs backup/target/fs local
data/to/be/back/upped zrep:src-fs data/to/be/back/upped local
data/to/be/back/upped zrep:master no local
Also, initialize the replication properties as in
<backupsrv> $ zrep changeconfig -f -d \
backup/target/fs \
client \
data/to/be/back/upped
Note that this is a reverse order in comparison to the backupee, the client.
Snapshot & Initialize Replication
Create an initial snapshot on the client to serve as the basis for datasset replication:
<backupee> $ zfs snap data/fs@zrep_000001
Initially, replicate the starting point to the backup server from the backup server
<backupsrv> $ ssh <backupee> \
zfs send data/to/be/back/upped@zrep_000001 \
| zfs recv -F backup/target/fs
Then, on the client, the initial, manual transfer must be announced to have been successful
<client> $ zrep sentsync -L data/to/be/back/upped
which also makes the backuppee the “master”, i.e., the reference.
Replicate and Backup
To prevent data from being written to the backup dataset on the server, first rollback and then set the readonly-property.
<backupsrv> $ zfs rollback backup/target/fs@zrep_000001
<backupsrv> $ zfs set readonly=on backup/target/fs
Now, backup by calling
<backupsrv> $ zrep refresh backup/target/fs
on the backup server.
Effects
Small backups, transferred by series of incremental snapshots, complete in ten to twenty seconds.
This seems large, but please consider that my disks dedicated to backup are among the slowest I have.
The corresponding rsync-based job takes nearly 400s and is thus slower by a factor of twenty, nearly entirely due to the penalties of heavy I/O on a large number of small files on slow disks.