Managing Secrets in Automated Environments
September 18, 2018. 5304 words.
Secure distribution of secrets is a problem affecting many who run automatic provisioning systems up to a point that the (re-)distribution of secrets to stages and/or environments is the major obstacle to (not even necessarily rapid) deployment.
For fear of an in(de)finite rant-loop, I do not wish to delve into the security impacts resulting directly therefrom - think of secrets compromised but not revoked because “there is no room for twenty-one story points in the next three sprints” - but instead suggest a methodical and structured way out.
With examples how to consume PKI certificates from Hashicorp’s Vault generically and by leveraging Kubernetes primitives, I hope to introduce the broader principles more stringently than in many blog posts which focus on usage in a specific scenario.
Provisioning Systems Automatically
When providing and/or provisioning machines and/or applications by an arbitrary automaton, the automatron employs some logic (viz. how to) on a given configuration (viz. what).
server {
listen 80;
server_name domain.tld;
root /var/www/html;
index index.html;
}Concretely, consider an arbitrary web server: There, the logic comprises the syntactical and semantic structure of configuration files, how to restart or reload the server and how to functionally ensure the availability of the service.
server {
listen <%= @port %>;
server_name <%= @domain %>;
root <%= @contentroot %>;
index <%= @indexpage %>;
}Thinking along that pattern, the logic may be expressed as a template file. The parameters to render the configuration file with may then be expressed in any structured data representation format.
---
webserver::port: 80
webserver::domain: domain.tld
webserver::root: /var/www/html
webserver::indexpage: index.htmlBoth logic (templates, renderers, etc.) and parameters are usually checked in into a version control system for source code, a repository.
Problem: Secret Parameters
Extending the example from above to a more life-like situation, consider the case when the traffic from that server is encrypted using https.
server {
listen 443 ssl;
server_name domain.tld;
ssl_certificate domain.tld.crt;
ssl_certificate_key domain.tld.key;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers HIGH:!aNULL:!MD5;
}While the location in terms of file names is not exactly secret, the files content, the certificate itself or the key certainly are. The same holds true for ssh-keys or login credentials to databases and/or machines to name but a few. It stands to reason that such secrets still may be parameters, but cannot be stored alongside publicly accessible non-secret parameters (well, they can, they should not).
Storage and Distribution of Secrets
What sets secrets apart from public information is that access to secrets should be prohibited by default and only be granted to a tightly controlled group of authorized personnel on a need-to-know basis. When everyone has access to secrets, they are not secret, but public.
Easily we can reach agreement, that even if it solves the access control problem, remembering secrets and not telling anyone is not feasible over a large and possibly rapidly changing number of secrets. The number of people with photographic memories is finite.
So, a mechanism needs to be established which stores information protected against loss against technical errors and against accidental or deliberate disclosure. This mechanism needs to be accessible and needs to allow for fine-grained access and modification control. Ideally, it should be accessible via network to allow for automated secret consumption alike to access to “normal”, non-secret parameters.
In the absence of such a mechanism, secrets need to be transported and installed by hand, thus bypassing automation.
Practice
In practice, secrets are often distributed manually, either directly or by proxy, viz., manually feeding them into a provisioning automaton. Storage in that case is left to the discretion of the authorized developer and most often, the local workstation or notebook will end up the dedicated storage location.
Inadvertently, secrets will spill over to locations not intended for storage of non-public information such as backup-systems or will be checked into the repositories for source code or binary artifacts by mistake.
In that state, firstly, the reasons why automation was introduced in the first place are in contradiction with the reality of human labour: Slow, difficult to reproduce, near impossible to audit, etc. Secondly, with such realities of secret storage, the so-called secrets will not be secret very long and could then well be stored permissively alongside the code and non-secret parameters in the source code repository, conveniently saving all that hassle on the way.
Dedicated Secret Store and Automatic Secret Distribution
To be able to automate machines or application in the presence of secrets, these need to be checked in by authorized personnel into a secrets store. Permissions to access that store need to be restrictive, but accessible to automation.
Ideally, secrets should be secret, viz., not known to anybody. Then, secrets should not be touched by humans and not be stored on machines less secure than the dedicated secret store. They should be short-lived, as over time secrets could end up in long-lived backups or accidentally logged.
The case can be made (and has in factArmon Dagar: Why We Need Dynamic Secrets. Hashicorp, Mar 2018. ) that so-called static secrets transported over media gaps are less suited than so-called dynamic secrets, which are automatically created on demand, timed-out, refreshed and revoked.
Installing Hashicorp Vault
A dedicated system to manage secrets in large and possibly dynamic environments exists with Hashicorp’s Vaultvaultproject.io. .
While the “Getting Started” Tour Hashicorp offersVault: Geting Started. is truly excellent, I would like to take a different angle, which I believe is better suited to learning by experimentation.
A very common scenario to run vault is using Hashicorp’s distributed key-value store Consulconsul.io. as storage backend.
Using a garden-variety docker-compose setup may be easiest for the start, I suggest using caultgithub.com, tolitius/cault.
Installing and starting vault boils then down to a simple docker-compose up -d.
version: '2'
services:
consul:
image: "consul:1.2.2"
...
ports:
- "8401:8400"
- "8501:8500"
- "8601:53/udp"
vault:
depends_on:
- consul
image: "vault:0.11.0"
...
volumes:
- ./tools/wait-for-it.sh:/wait-for-it.sh
- ./config/vault:/config
- ./config/vault/policies:/policies
...Depending on the local setup, it may be advisable to change local-port redirection to prevent port collisions with local instances - I use consul for service discovery in my local LAN. I also advise to enforce pulling the latest releases and suggest to note where local files will be available in the container.
Because vault then runs inside a container, it may be handy setting a shell alias.
alias vault='docker exec -it cault_vault_1 vault "$@"'
Increasingly, applications communication without TLS are of limited value, so I suggest practicing and demonstrating with https endpoints from the start, for instance using Let’sEncrypt certificates.
When testing locally and without having certificates with IP Subject Alternative Names, providing the necessary name resolution can easily be accomplished using /etc/hosts.
The corresponding configuration of vault is easy to supply.
listener "tcp" {
address = "0.0.0.0:8200"
tls_disable = 0
tls_cert_file = "/froot/star_hb22_cruwe_de/fullchain.pem"
tls_key_file = "/froot/star_hb22_cruwe_de/privkey.pem"
}Initializing Vault
Vault needs to be initialized before operation. To fulfill the requirement of protecting secret data against loss, data is encrypted before being written to any kind of persistent storage. Keys are generated upon initialization and split using Shamir’s Secret Sharing method so that unlocking the vault and thus access to the secrets requires a quorum of authorized personnel.Remember hunting Red October: “The reason for having two missile keys is so that no one man may fire the missiles.” Because the vault’s operator, the person factually performing the initialization, will know the key material otherwise, the keys may be passed transparently and asymmetrically encrypted to the operator using PGP.
The root token should be used for further vault operations and the unseal keys securely stored.
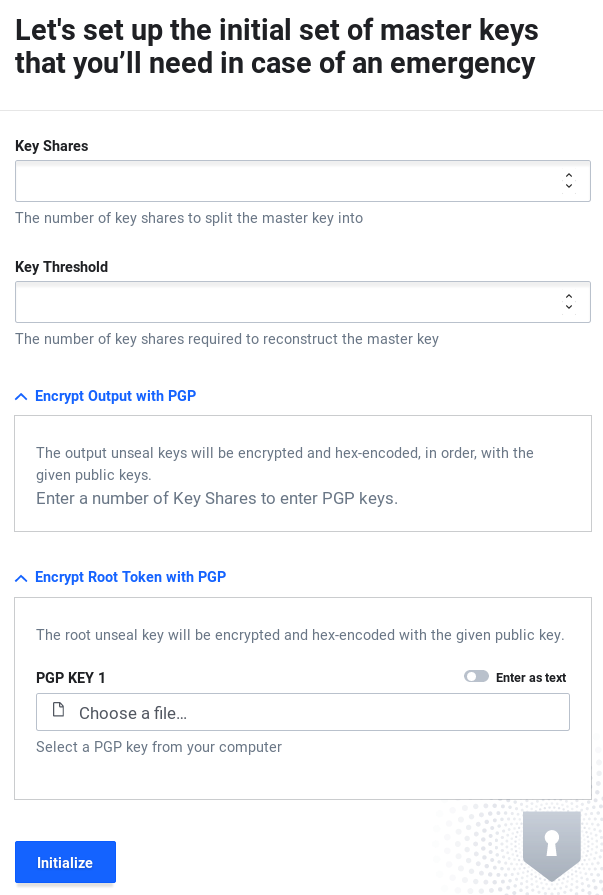
Initializing Vault.
$ vault operator init
-key-shares=5 \
-key-threshold=3
Unseal Key 1: UTQSY5SIgo43jo5/kpaWWYqWrxMBu2jMQRpFEg3tQrqF
Unseal Key 2: 9XDg1hKUp8UCphNuBJ6L7etx5XdFfY9shYGDFhjFZwBx
Unseal Key 3: Qsca6DosbPLZQLdA3gGanMq8vroH3mkuy7d7fBepkhTl
Unseal Key 4: NtyNTy5rHFiPtqTqf0MAc1+b45oecf3aM7wvoYOQw/3o
Unseal Key 5: 0jVhoO8zBaLVIS5sB/iKJJVeITOHroOIsjASOwvpowNt
Initial Root Token: b19aba3d-fb07-694f-5c72-ed47dbacacd2or
$ vault operator init \
-key-shares=5 \
-key-threshold=3 \
-pgp-keys="keybase:cjr@,keybase:..." \
-root-token-pgp-key="keybase:cjr@"
...Apart from shell operations, vault may be initialized from the web UI, which I for sake of reproducibility I advise against.
The vault may then be unsealed issuing vault operator unseal, a session may be established
$ vault operator unseal
$ vault loginVault Components
Vault is structured around backends for secrets and authentication. Secret backends allow to provider or generate secrets for different consumers and may vary in their degree of specialization. For instance, one backend is responsible for simple key-value pairs and another backend generates and injects login credentials into database management systems. Yet another backend generates short lived certificates on a preconfigured certificate authority, which consumers may be set to trust.
Secrets are released to consumers on authentication and authorization only. Authentication backends provide different methods for different usage patterns. These may either consist of “classical” username-password credentials or web-token, but may expand to the needs of specific application orchestration frameworks. For instance, it is possible to register the authentication engine of a Kubernetes cluster at a vault instance, which may then provide authentication credentials to applications orchestrated by the cluster as consumers.
Using the PKI Secret Engine to Generate Certificates
An example relatively straight-forward to demonstrate and grasp in practice is Vault’s Certificate Engine.Vault: PKI. Vault may be setup as root or interim certificate authority and will then generate certificates against this CA, so that authorized members of a communication system may cryptographically verify and secure their interactions based on a mutually shared trust.
Enabling and configuring PKI engine
$ vault secrets enable pki
Success! Enabled the pki secrets engine at: pki/
$ vault secrets tune \
-default-lease-ttl=1h \
-max-lease-ttl=36h \
pki
Success! Tuned the secrets engine at: pki/For vault, engines must be enabled and pre-configured.
Separate instances of the same backend type may be created supplying the -path=<name> parameter, which allows to separate on configuration of secret and/or usage policies.
At least in relatively volatile container environments, where applications scale horizontally on changes in load, certificates are short-lived.
When exiting, applications will revoke their certificate and when certificates are short-lived, CRLs may be periodically pruned and thus kept short.
Also, left-overs from failed revocation at application shutdown events may then time-out instead of polluting the validity checks until eternity.
{
"request_id": "5f660ab9-1b98-d4bf-8c31-e06994c2beb7",
"lease_id": "",
"lease_duration": 0,
"renewable": false,
"data": {
"certificate": "-----BEGIN CERTIFICATE-----\nMIIEbjCCA1agAwIBAgIUaQli9Prkerqq4CQDfUUYWbr0e2swDQYJKoZIhvcNAQEL\nBQAwgZwxEDAOBgNVBAYMB25vX2NpdHkxFzAVBgNVBAgMDm5vX2NpdHlfcmVhbGx5\nMSIwIAYDVQQHDBlub190aGFua195b3VfaV9hbV9tYXJyaWVkMSIwIAYDVQQKDBlu\nb25lX2p1c3RfbG9va19hdF9teV9kZXNrMQ8wDQYDVQQLEwZNeXNlbGYxFjAUBgNV\nBAMTDWhiMjIuY3J1d2UuZGUwHhcNMTgwOTE0MTA0NTQ5WhcNMTgwOTE1MjI0NjE5\nWjCBnDEQMA4GA1UEBgwHbm9fY2l0eTEXMBUGA1UECAwObm9fY2l0eV9yZWFsbHkx\nIjAgBgNVBAcMGW5vX3RoYW5rX3lvdV9pX2FtX21hcnJpZWQxIjAgBgNVBAoMGW5v\nbmVfanVzdF9sb29rX2F0X215X2Rlc2sxDzANBgNVBAsTBk15c2VsZjEWMBQGA1UE\nAxMNaGIyMi5jcnV3ZS5kZTCCASIwDQYJKoZIhvcNAQEBBQADggEPADCCAQoCggEB\nAO85O0hhB8aszjHEtxaVWfwEIj+WRsmsh7pxxrtZg/I01IU61xi2vxxJ2cK4Z7Us\nKDHE7zS2LECzvhcG1vT3qToe1Dv+FboHySFH93KDidS8q47DbUJOk+JwhN7cDcmx\nDh2Dlxxnn9/MRmoZozYPc4JlBMkq3/UrwSlaMkvSWguUssWTksx8CT50bpDPEbJI\n3riNhaHy5AYbD8kJYaBsLNCkMc5P6xlvJUH5afn9lluyH27MLUS7635+sXeDEHNS\nMzEoHMZxGxuaMXX4a+qw6Lr+gbf/Dl+eJBFZN+YLk0mbEcfLBE0v4b4Fs3S9IObs\nQtfabLgtTvpCbhx2XkWrMC0CAwEAAaOBpTCBojAOBgNVHQ8BAf8EBAMCAQYwDwYD\nVR0TAQH/BAUwAwEB/zAdBgNVHQ4EFgQU6NtunW43/QAwZp3HSQRoZtM5AYUwHwYD\nVR0jBBgwFoAU6NtunW43/QAwZp3HSQRoZtM5AYUwHgYDVR0RBBcwFYINaGIyMi5j\ncnV3ZS5kZYcEfwAAATAfBgNVHR4BAf8EFTAToBEwD4INaGIyMi5jcnV3ZS5kZTAN\nBgkqhkiG9w0BAQsFAAOCAQEASbDOcmsqccT9D8KRYwa9Cupn4bZKWoNY6E6Dv7Cd\nPPZ42eOJCwjZMZiKPd+JxBVhUmeHFbfztszelH9piCGFysBaO3/PAhdMRAyki/h9\nZ8tIUdFxXU+podfp31MwHyjDnPn08B9Erp3HXPI8D700hmuLnOkuK/LOcVDyC9k/\nGZd9IuSUDEj9uJnKqvsUw2EuMdkoJtnJt9AgLmUx38lB1BJ8tC4x5yyKFyxXZ5//\nHpPJHhDVOQktoAp2215puFxbhJDKWbmiwU1eNvZDzQ7x5mxpZQQW2TXVO8H59dJB\nTWbVHsDvGM7iRbhQ3RTp/WAcp2xQrDFS26OxQ7oh3KtONA==\n-----END CERTIFICATE-----",
"expiration": 1537051579,
"issuing_ca": "-----BEGIN CERTIFICATE-----\nMIIEbjCCA1agAwIBAgIUaQli9Prkerqq4CQDfUUYWbr0e2swDQYJKoZIhvcNAQEL\nBQAwgZwxEDAOBgNVBAYMB25vX2NpdHkxFzAVBgNVBAgMDm5vX2NpdHlfcmVhbGx5\nMSIwIAYDVQQHDBlub190aGFua195b3VfaV9hbV9tYXJyaWVkMSIwIAYDVQQKDBlu\nb25lX2p1c3RfbG9va19hdF9teV9kZXNrMQ8wDQYDVQQLEwZNeXNlbGYxFjAUBgNV\nBAMTDWhiMjIuY3J1d2UuZGUwHhcNMTgwOTE0MTA0NTQ5WhcNMTgwOTE1MjI0NjE5\nWjCBnDEQMA4GA1UEBgwHbm9fY2l0eTEXMBUGA1UECAwObm9fY2l0eV9yZWFsbHkx\nIjAgBgNVBAcMGW5vX3RoYW5rX3lvdV9pX2FtX21hcnJpZWQxIjAgBgNVBAoMGW5v\nbmVfanVzdF9sb29rX2F0X215X2Rlc2sxDzANBgNVBAsTBk15c2VsZjEWMBQGA1UE\nAxMNaGIyMi5jcnV3ZS5kZTCCASIwDQYJKoZIhvcNAQEBBQADggEPADCCAQoCggEB\nAO85O0hhB8aszjHEtxaVWfwEIj+WRsmsh7pxxrtZg/I01IU61xi2vxxJ2cK4Z7Us\nKDHE7zS2LECzvhcG1vT3qToe1Dv+FboHySFH93KDidS8q47DbUJOk+JwhN7cDcmx\nDh2Dlxxnn9/MRmoZozYPc4JlBMkq3/UrwSlaMkvSWguUssWTksx8CT50bpDPEbJI\n3riNhaHy5AYbD8kJYaBsLNCkMc5P6xlvJUH5afn9lluyH27MLUS7635+sXeDEHNS\nMzEoHMZxGxuaMXX4a+qw6Lr+gbf/Dl+eJBFZN+YLk0mbEcfLBE0v4b4Fs3S9IObs\nQtfabLgtTvpCbhx2XkWrMC0CAwEAAaOBpTCBojAOBgNVHQ8BAf8EBAMCAQYwDwYD\nVR0TAQH/BAUwAwEB/zAdBgNVHQ4EFgQU6NtunW43/QAwZp3HSQRoZtM5AYUwHwYD\nVR0jBBgwFoAU6NtunW43/QAwZp3HSQRoZtM5AYUwHgYDVR0RBBcwFYINaGIyMi5j\ncnV3ZS5kZYcEfwAAATAfBgNVHR4BAf8EFTAToBEwD4INaGIyMi5jcnV3ZS5kZTAN\nBgkqhkiG9w0BAQsFAAOCAQEASbDOcmsqccT9D8KRYwa9Cupn4bZKWoNY6E6Dv7Cd\nPPZ42eOJCwjZMZiKPd+JxBVhUmeHFbfztszelH9piCGFysBaO3/PAhdMRAyki/h9\nZ8tIUdFxXU+podfp31MwHyjDnPn08B9Erp3HXPI8D700hmuLnOkuK/LOcVDyC9k/\nGZd9IuSUDEj9uJnKqvsUw2EuMdkoJtnJt9AgLmUx38lB1BJ8tC4x5yyKFyxXZ5//\nHpPJHhDVOQktoAp2215puFxbhJDKWbmiwU1eNvZDzQ7x5mxpZQQW2TXVO8H59dJB\nTWbVHsDvGM7iRbhQ3RTp/WAcp2xQrDFS26OxQ7oh3KtONA==\n-----END CERTIFICATE-----",
"serial_number": "69:09:62:f4:fa:e4:7a:ba:aa:e0:24:03:7d:45:18:59:ba:f4:7b:6b"
},
"warnings": null
}$ vault write \
-format=json \
pki/root/generate/internal \
common_name=hb22.cruwe.de \
format=pem \
ip_sans=127.0.0.1 \
key_bits=2048 \
key_type=rsa \
permitted_dns_domains=hb22.cruwe.de \
private_key_format=pem \
ttl=720h \
\
ou=Myself \
organization=none_just_look_at_my_desk \
country=no_city \
locality=no_thank_you_i_am_married \
province=no_city_really \
| tee pki-ca.jsonBeing a modern application for web usage, output may be passed as JSON, allowing easy filtering with tools such as
jq -r '.data.certificate' | openssl x509 -text to generate a human-readable representation of the certificate just generated.
Configuring paramters for issuer endpoints
$ vault write pki/config/urls \
issuing_certificates="http://vault:8200/v1/pki/ca" \
crl_distribution_points="http://vault:8200/v1/pki/crl"Certificates should include endpoints where the certificates are issued and where to check if certificates presented my an untrusted party have been revoked at the CA, i.e., are invalid.
$ vault write pki/roles/hb22 \
allow_glob_domains=true \
allow_ip_sans=false \
allow_subdomains=true \
allowed_domains=hb22.cruwe.de \
max_ttl=36h \
ttl=1hSecret “roles” (not to be confused with authentication roles) represent
configuration and match an issuer path, so that for instance pki/roles/hb22 corresponds to pki/issue/hb22.
They govern what certificate parameters the PKI-backend should enforce when called via the corresponding issuer endpoint.
Parameters set at the endpoint of the engine may be altered, but not exceeded, so that the maximum TTL at the role configuration may not exceed the maximum TTL at the secret backend.
Configuring Authentication for Consumers of Secrets
Authentication endpoints need to be enabled as with secret backends.Vault: Authentication.
For instance, the approle authenticator is well suited for applications, i.e., non-interactive secret consumption by e.g. an application and/or machine provisioning automaton.
$ vault auth enable approle
Success! Enabled approle auth method at: approle/path "pki/*" {
capabilities = [
"create",
"list",
"read",
"update",
]
}Policies may be in place which set permissions how to interact with the authentication endpoint. Authentication roles may be bound to policies and other restrictions, such as CIDR addresses.
$ vault policy write hb22certmanager /froot/hb22certmanager.hcl
Success! Uploaded policy: hb22certmanager
$ vault write auth/approle/role/hb22certmanager \
policies=hb22certmanager \
bound_cidr_list=192.168.2.0/24,192.168.33.0/24,172.19.0.0/24 \
token_bound_cidrs=192.168.2.0/24,192.168.33.0/24,172.19.0.0/24“Logging in” and obtaining certificates
Then, the role can be used to collect a web token which will grant permissions on the PKI secret endpoint.
{
"request_id": "7d7edcfd-ff16-75ac-8fe2-ebfeb7b35402",
"lease_id": "",
"lease_duration": 0,
"renewable": false,
"data": {
"role_id": "f489209e-3834-1b7c-389d-85a525f8c3a0"
},
"warnings": null
}{
"request_id": "ec1ddcbd-8af5-3ffd-639f-d83ade5b9acd",
"lease_id": "",
"lease_duration": 0,
"renewable": false,
"data": {
"secret_id": "9e789e87-72c5-fde0-e617-ca35959e85e7",
"secret_id_accessor": "db9a153c-072e-5195-4e45-136b77b1bf2a"
},
"warnings": null
}Practically, first role-id and corresponding secret are gathered
$ vault read \
-format=json \
auth/approle/role/hb22certmanager/role-id \
| tee role.json$ vault write \
-format=json \
-force \
auth/approle/role/hb22certmanager/secret-id \
| tee secret.jsonand then used to obtain a web-token representing the login session:
{
"request_id": "b8c56cac-059b-f5ed-8f2a-7751d771fe42",
"lease_id": "",
"renewable": false,
"lease_duration": 0,
"data": null,
"wrap_info": null,
"warnings": null,
"auth": {
"client_token": "63cfcf7d-a034-0cdb-6f35-ae9dc05e646c",
"accessor": "9e36ba3f-0338-ce3a-0704-7996a4e45004",
"policies": [
"default",
"hb22certmanager"
],
"token_policies": [
"default",
"hb22certmanager"
],
"metadata": {
"role_name": "hb22certmanager"
},
"lease_duration": 2764800,
"renewable": true,
"entity_id": "228bb249-8fd1-26da-9580-b95381ffec53"
}
}$ curl \
--request POST \
--data "
{
\"role_id\": $(jq '.data.role_id' role.json),
\"secret_id\": $(jq '.data.secret_id' secret.json)
}
" \
https://vault.hb22.cruwe.de:8200/v1/auth/approle/login \
| jq '.' \
| tee login.jsonThe client token then will map to the permissions present in the auth-dictionary amd can be used to read a secret from the issuer endpoint pki/issue/hb22.
$ curl \
--header "X-Vault-Token: $(jq -r '.auth.client_token' login.json)" \
--request POST \
--data '
{
"common_name": "mccarthy.hb22.cruwe.de"
}
' \
"https://vault.hb22.cruwe.de:8200/v1/pki/issue/hb22" \
| jq '.' \
| tee cert.json
$ jq -r '.data.certificate' cert.json \
| openssl x509 -text
$ jq -r '.data.certificate' cert.json \
> cert.crtAgain, the certificate may be examined and extracted for later use calling jq.
Authenticating with Kubernetes Service Account Tokens
Vault backends may be very general or the may be specifically tailored to the needs of one application.
An example for such a backend is the Kubernetes authentication backend.
Here, “service accounts”, which represent “technical users” in Kubernetes may be given permissions to the auth-delegator role.
Then, applications run with this technical user’s permissions may consume web-tokens for authentication from Kubernetes, which will be accepted by the corresponding Vault authentication endpoint.
Configure Kubernetes and Kubernetes Authentication Backend
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: demowebserver---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: auth-delegator
namespace: default
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: demowebserver
namespace: defaultHaving created a service account, a backend can be created with the account’s tokens and the Kubernetes certificate authority,
DEMO_TOKEN_NAME=$(\
kubectl get sa demowebserver \
-o jsonpath="{.secrets[*]['name']}" \
)
DEMO_JWT_TOKEN=$(\
kubectl get secret \
$DEMO_TOKEN_NAME \
-o jsonpath="{.data.token}" \
| base64 --decode \
)
DEMO_CA_CRT=$(\
kubectl get secret \
$DEMO_TOKEN_NAME \
-o jsonpath="{.data['ca\.crt']}" \
| base64 --decode\
)
K8S_HOST=192.168.99.33so that
vault auth enable kubernetes
vault write auth/kubernetes/config \
token_reviewer_jwt="$DEMO_JWT_TOKEN" \
kubernetes_host="https://$K8S_HOST:6443" \
kubernetes_ca_cert="$DEMO_CA_CRT"
vault write auth/kubernetes/role/demowebserver \
bound_service_account_names=demowebserver \
bound_service_account_namespaces=default \
policies=hb22certmanager \
ttl=24hwill yield a backend which can by means of the policy passed issue certificates to applications running under this service account.
USing Kubernetes Service Account Tokens to Obtain Certificates
apiVersion: v1
kind: Pod
metadata:
name: debugger
labels:
app: debugger
spec:
containers:
- name: debugger
command:
- "/bin/sleep"
- "3600"
image: artifactory.hb22.cruwe.de:8082/cjr-base
imagePullPolicy: IfNotPresent
hostAliases:
- ip: "192.168.99.1"
hostnames:
- "vault.hb22.cruwe.de"
- "vault"
restartPolicy: Always
serviceAccountName: demowebserverAssuming a baseimage with curl and jq installed, this may be tested manually in the context of a trivial pod, first extracting the service accounts’s token, always present at /var/run/secrets/kubernetes.io/serviceaccount/token, and then passing that token the Kubernetes authentication endpoint to obtain a login.
{
"request_id": "8b8aae2c-82f2-7c57-09f0-cca6f23e8da1",
"lease_id": "",
"renewable": false,
"lease_duration": 0,
"data": null,
"wrap_info": null,
"warnings": null,
"auth": {
"client_token": "53915374-1512-2783-122b-b84bf72e484e",
"accessor": "20ac7186-3754-4005-37f3-3b63370182ab",
"policies": [
"default",
"demowebserver"
],
"token_policies": [
"default",
"hb22certmanager"
],
"metadata": {
"role": "demowebserver",
"service_account_name": "demowebserver",
"service_account_namespace": "default",
"service_account_secret_name": "demowebserver-token-p4hxn",
"service_account_uid": "151521df-b814-11e8-9c20-080027ee1df7"
},
"lease_duration": 300,
"renewable": true,
"entity_id": "9296c0c2-c98b-1601-f781-a4924dbc85c5"
}
}$ kubectl exec -ti debugger /bin/bash
root@debugger:/# TOKEN=$(\
cat /var/run/secrets/kubernetes.io/serviceaccount/token \
)
root@debugger:/# curl \
--request POST \
--data "\
{
\"jwt\": \"${TOKEN}\",
\"role\": \"demowebserver\"
}
"\
https://vault.hb22.cruwe.de:8200/v1/auth/kubernetes/login \
| tee login.json \
| jq '.'{
"request_id": "cc53c797-c6d4-02f2-8bc9-adea52c75451",
"lease_id": "",
"renewable": false,
"lease_duration": 0,
"data": {
"certificate": "-----BEGIN CERTIFICATE-----\nMIIESjCCAzKgAwIBAgIUGwYLJ/sJNts5wmvM4yH7fLctdcwwDQYJKoZIhvcNAQEL\nBQAwgZwxEDAOBgNVBAYMB25vX2NpdHkxFzAVBgNVBAgMDm5vX2NpdHlfcmVhbGx5\nMSIwIAYDVQQHDBlub190aGFua195b3VfaV9hbV9tYXJyaWVkMSIwIAYDVQQKDBlu\nb25lX2p1c3RfbG9va19hdF9teV9kZXNrMQ8wDQYDVQQLEwZNeXNlbGYxFjAUBgNV\nBAMTDWhiMjIuY3J1d2UuZGUwHhcNMTgwOTE0MTI1NDU0WhcNMTgwOTE1MDA1NTI0\nWjAhMR8wHQYDVQQDExZtY2NhcnRoeS5oYjIyLmNydXdlLmRlMIIBIjANBgkqhkiG\n9w0BAQEFAAOCAQ8AMIIBCgKCAQEAovlDBv60sJffi+Ow610gu1/ZhUmUzkmMfGyx\nzFtlXzMrhjTnrYRSihqWePR/U41jVAe3xFDtRXoQotmveRsdMmwndA1OLONzfLOO\nif2AvNAeFWCsO0RguclJHwBjnUXKn3XIxZku+QDhOGGn8g27qix2E4JrCx3zqQcT\nfZDd6dc5kF5fUJesVQcDgPmEKnySpBa7cM/5CmtVHDvNya49NXJnAV1SZium6Rxd\n+l/OKPH0eMbhIW6W9Dfo8HZHZq2GIwjthoOWqL7+cAJeM3M23gMQbGjMU8Y95bUA\nYWjLDZ7fARC+9yvXvr6ZyJcAzw3RkuAp21+WoQxcLzI7MxnB6wIDAQABo4H9MIH6\nMA4GA1UdDwEB/wQEAwIDqDAdBgNVHSUEFjAUBggrBgEFBQcDAQYIKwYBBQUHAwIw\nHQYDVR0OBBYEFK0oLOvtOrYNgAcPndtjEvTitR8LMB8GA1UdIwQYMBaAFOjbbp1u\nN/0AMGadx0kEaGbTOQGFMDcGCCsGAQUFBwEBBCswKTAnBggrBgEFBQcwAoYbaHR0\ncDovL3ZhdWx0OjgyMDAvdjEvcGtpL2NhMCEGA1UdEQQaMBiCFm1jY2FydGh5Lmhi\nMjIuY3J1d2UuZGUwLQYDVR0fBCYwJDAioCCgHoYcaHR0cDovL3ZhdWx0OjgyMDAv\ndjEvcGtpL2NybDANBgkqhkiG9w0BAQsFAAOCAQEAdmAjBFbCtb8BHMbVBnRwQzEg\n2byOEKAiPn7H48C4Hy6pdwV3ULb2b+TLazYtkGaygMAdEwysPbvgWpw6awvxEerp\ngYJfhZ4ZnHmaYFPbAWAxL3bI6REla2jifWCuzt5MetyFK+3vjqAQS69OSQcjnn5R\nbvU021gp2+wWmfW9+9JCmyNaVDCcJV0mMuhY6bwpq8XI0+I3MeiHXMrqZLh2n+Fv\nfCrANWKvhsAg80eOF84RFrHJi2qdieXNwuM3yDeniDeWdJCvt3yWAUJBq5d8aT69\njEHPAS491XDK91YY+HMukAtE2wkuyck+HUgLxz728wtpFnWopKMMqS91NhKXkA==\n-----END CERTIFICATE-----",
"issuing_ca": "-----BEGIN CERTIFICATE-----\nMIIEbjCCA1agAwIBAgIUaQli9Prkerqq4CQDfUUYWbr0e2swDQYJKoZIhvcNAQEL\nBQAwgZwxEDAOBgNVBAYMB25vX2NpdHkxFzAVBgNVBAgMDm5vX2NpdHlfcmVhbGx5\nMSIwIAYDVQQHDBlub190aGFua195b3VfaV9hbV9tYXJyaWVkMSIwIAYDVQQKDBlu\nb25lX2p1c3RfbG9va19hdF9teV9kZXNrMQ8wDQYDVQQLEwZNeXNlbGYxFjAUBgNV\nBAMTDWhiMjIuY3J1d2UuZGUwHhcNMTgwOTE0MTA0NTQ5WhcNMTgwOTE1MjI0NjE5\nWjCBnDEQMA4GA1UEBgwHbm9fY2l0eTEXMBUGA1UECAwObm9fY2l0eV9yZWFsbHkx\nIjAgBgNVBAcMGW5vX3RoYW5rX3lvdV9pX2FtX21hcnJpZWQxIjAgBgNVBAoMGW5v\nbmVfanVzdF9sb29rX2F0X215X2Rlc2sxDzANBgNVBAsTBk15c2VsZjEWMBQGA1UE\nAxMNaGIyMi5jcnV3ZS5kZTCCASIwDQYJKoZIhvcNAQEBBQADggEPADCCAQoCggEB\nAO85O0hhB8aszjHEtxaVWfwEIj+WRsmsh7pxxrtZg/I01IU61xi2vxxJ2cK4Z7Us\nKDHE7zS2LECzvhcG1vT3qToe1Dv+FboHySFH93KDidS8q47DbUJOk+JwhN7cDcmx\nDh2Dlxxnn9/MRmoZozYPc4JlBMkq3/UrwSlaMkvSWguUssWTksx8CT50bpDPEbJI\n3riNhaHy5AYbD8kJYaBsLNCkMc5P6xlvJUH5afn9lluyH27MLUS7635+sXeDEHNS\nMzEoHMZxGxuaMXX4a+qw6Lr+gbf/Dl+eJBFZN+YLk0mbEcfLBE0v4b4Fs3S9IObs\nQtfabLgtTvpCbhx2XkWrMC0CAwEAAaOBpTCBojAOBgNVHQ8BAf8EBAMCAQYwDwYD\nVR0TAQH/BAUwAwEB/zAdBgNVHQ4EFgQU6NtunW43/QAwZp3HSQRoZtM5AYUwHwYD\nVR0jBBgwFoAU6NtunW43/QAwZp3HSQRoZtM5AYUwHgYDVR0RBBcwFYINaGIyMi5j\ncnV3ZS5kZYcEfwAAATAfBgNVHR4BAf8EFTAToBEwD4INaGIyMi5jcnV3ZS5kZTAN\nBgkqhkiG9w0BAQsFAAOCAQEASbDOcmsqccT9D8KRYwa9Cupn4bZKWoNY6E6Dv7Cd\nPPZ42eOJCwjZMZiKPd+JxBVhUmeHFbfztszelH9piCGFysBaO3/PAhdMRAyki/h9\nZ8tIUdFxXU+podfp31MwHyjDnPn08B9Erp3HXPI8D700hmuLnOkuK/LOcVDyC9k/\nGZd9IuSUDEj9uJnKqvsUw2EuMdkoJtnJt9AgLmUx38lB1BJ8tC4x5yyKFyxXZ5//\nHpPJHhDVOQktoAp2215puFxbhJDKWbmiwU1eNvZDzQ7x5mxpZQQW2TXVO8H59dJB\nTWbVHsDvGM7iRbhQ3RTp/WAcp2xQrDFS26OxQ7oh3KtONA==\n-----END CERTIFICATE-----",
"private_key": "-----BEGIN RSA PRIVATE KEY-----\nMIIEowIBAAKCAQEAovlDBv60sJffi+Ow610gu1/ZhUmUzkmMfGyxzFtlXzMrhjTn\nrYRSihqWePR/U41jVAe3xFDtRXoQotmveRsdMmwndA1OLONzfLOOif2AvNAeFWCs\nO0RguclJHwBjnUXKn3XIxZku+QDhOGGn8g27qix2E4JrCx3zqQcTfZDd6dc5kF5f\nUJesVQcDgPmEKnySpBa7cM/5CmtVHDvNya49NXJnAV1SZium6Rxd+l/OKPH0eMbh\nIW6W9Dfo8HZHZq2GIwjthoOWqL7+cAJeM3M23gMQbGjMU8Y95bUAYWjLDZ7fARC+\n9yvXvr6ZyJcAzw3RkuAp21+WoQxcLzI7MxnB6wIDAQABAoIBADVgwKRU3ieMxqoR\nvEuKaAMW5K60J+ncywehriZJtQ0WPGYrg8ogMcyL4sbhBab/Aw5trLG+88eysCo2\ndDONPuXZ6J4pEXbAVH3+bWwivHybCY9k52ROBAQ1uh5OSVIknrXVpRmbD3h84kdO\nLOyptNKK122SZK7yc3DkIW0Z+qTw1CJk2eTc9y3ZmXfYeuG5PHdlRCxku1etbQOA\nlvw5oNePTIrhsi6VVg8ZcBggbyPCjH5T8QZ1yaErO2hRDXUeN6TTtrFrb57EXDQh\nEtDYi1TdlHBKqMi4Z/e9EkXUVaJlz4lLiM5BUjUPd1/J3iATaxibQUgbe0gbW2MX\nPNtXbikCgYEA2Gs8yjEb38op0I2a1l3RqQB30voSqlCHnz0TqdwQsVQDxUt3Hfd3\nd+vwuidx+OckhB45ax3aBBn/Q6S0TQSyPFWaOnvJUWNumgYMAR43Hl90Tc+dS5Cy\nl6TQ9jvfKNrz2uL0of+wbZ2d8g6YWoTHbKpBuKs5TAYgzHUdOSfE8kcCgYEAwMe2\nQOPptk1KbdZ/JVLHS5I2HbIDyKIA8hnQxhHXKXlD7xlHbZGF0WjGwJVrF76OZ6Yf\n/AOeTfRFKVmuqPWQCX6tneggq4yQAgoI+zpVXZdLRuznQTnBBvBjHX4PW9LPcKiP\n/SAygMXoDyxLXHRbUqxEZjMWFzst7QicIncYQT0CgYEApTbgln59CA/+cf7YWJQQ\nzZLU5tQP0cNedbsbus2MVMONiV1+FvtnUb5l7MbWJCzY3J9yOAr297CdBZfEKRPP\nuW2kKsd7Pc3Jjn3VRjk53M8EK662JwzUuh2RhJjaWQclqFEgbleS6WutOy/XMSsy\nTwt+1qqoOBhpi4xQfeSVXlsCgYAqPNeSuhzfw2l2TVPIQq3FwgA3W2R21f/tC3jx\nnMEOpjIbNeevev3d1t4NHe+74RVkYkKJveU2YTmyCKM7A6qOWgICIfTegUqgF8DG\nAo7nlZl5rbgxU00Wjx64PIFy9epbXaNGq4JFMpdYk7TjSd8kavgFiFXjuySh1YwY\nBQ38ZQKBgEBm+C60lWbQYhybtp7bwBWAT/z98fYq1/VxKrH+IG9tG/lcK/LjLKYB\nBcyENWSGjYPrTA4262ySL930n5s2exMVyuebWBzlSspNdyz4F/6u+taValmmCCvK\nmrD+hd7w2uxZRm3hdEwXtZGZqSdae3dgP0pDAbWeSs3buH/IYWmt\n-----END RSA PRIVATE KEY-----",
"private_key_type": "rsa",
"serial_number": "1b:06:0b:27:fb:09:36:db:39:c2:6b:cc:e3:21:fb:7c:b7:2d:75:cc"
},
"wrap_info": null,
"warnings": null,
"auth": null
}Passing the client token present therein in the X-Vault-Token header to the issuer endpoint will grant permissions as in the token’s .auth.policies and auth.token_policies section and will obtain a certificate signed by the Vault PKI CA.
root@debugger:/# curl \
--header "X-Vault-Token: $(jq -r '.auth.client_token' login.json)" \
--request POST \
--data '
{
"common_name": "mccarthy.hb22.cruwe.de"
}
' \
"https://vault.hb22.cruwe.de:8200/v1/pki/issue/hb22" \
| jq '.' \
| tee cert.jsonThe certifcate can again be examined calling
jq -r '.data.certificate' cert.json | openssl x509 -textAutomating Certificate Distribution
The idea is to have two simple scripts present in all containers run in Kubernetes, which obtain secrets and unmarshal the JSON payload returned by vault.
The idea is as simple as the manual demonstration: Pass the service account’s token to the login endpoint, obtain a client token and then obtain an X509 certificate. Store the certificate at a predefined location and then run the application which requires the certificate. Done.
apiVersion: apps/v1
kind: Deployment
...
spec:
...
spec:
containers:
- name: demowebserver
image: cjr-webserver
volumeMounts:
- mountPath: /var/secrets
name: secrets
initContainers:
- name: certificator
image: cjr-certificator
volumeMounts:
- mountPath: /var/secrets
name: secrets
serviceAccountName: demowebserver
volumes:
- name: secrets
emptyDir: {}Two get the desired sequence and to pass the secret to the consumer, we use two Kubernetes primitives, the initContainer, which run before the main containers of a pod are started and the emtpyDir volume, which represents a directory shared between a pod’s containers.
Here, the mountpoint /var/secrets is shared by both containers and
TOKEN=$(jq -r '.auth.client_token' ${MNT}/login.json)
curl \
--header "X-Vault-Token: ${TOKEN}" \
--request POST \
--data ${DATA} \
${SECRET_ENDPOINT} \
| tee ${MNT}/${SECRET_OBJ}.jsonwill place a freshly generated certificate therein.
spec:
containers:
- name: demowebserver
command:
- unwrapCert
- run
image: cjr-webserver
volumeMounts:
- mountPath: /var/secrets
name: secrets
initContainers:
- name: certificator
command:
- getCert
- with paramters as such
image: cjr-certificator
volumeMounts:
- mountPath: /var/secrets
name: secrets
serviceAccountName: demowebserver
volumes:
- name: secrets
emptyDir: {}The consuming applications will then just need to unmarshal the certificate and key from the JSON-payload
jq -r '.data.certificate' ${MNT}/${SECRET_OBJ} \
| tee ${TARGET}/${NAME}.crt
jq -r '.data.private_key' ${MNT}/${SECRET_OBJ} \
| tee ${TARGET}/${NAME}.keyand may start running.
To get that orchestration, it suffices to amend the pod specs.
Refreshing secrets
Because certificates are short-lived and may be valid shorter than the application’s instance will live, a certificate needs to be refreshed regularly.
In many cases, this may be as trivial as running the certificate getter und unmarshal code in a sleep-loop, SIGHUP-ing the application on new certificates, although sending kill to a secret consumer in the fashion common on physical hosts requires alpha-state PodShareProcessNamespace to be enabled.Kubernetes > v1.10: Share Process Namespace between Containers in a Pod.
A in my opinion more elegant pattern is to use a so-called sidekick container to continuously watch login leases and certificates and refresh either when necessary.
On the consuming pod, it then suffices to set an inotify watch on the JSON secrets package and unmarshal and SIGHUP there.
inotifywait \
-e modify \
-m ${MNT}/${SECRET_OBJ} \
| while read change
do
unwrapCert
kill -s SIGHUP $pid
doneAbstractions
Regardless of the secret consumed, certificate, database credentials or others, having secrets provisioned with human intervention thus causes the first leak in the handling process. Having secrets handled exclusively by machines and meticulously logging each interaction greatly enhances the overall security of the system protected. Concepts, mechanisms and technologies behind such automated handling are straightforward and, reduced to the necessary, easy to apply.
So, not primarily speed, but reproducibility and auditability may be reaped by eliminating human intervention from the deployment process, even when the management of secret is considered.